Introduction
The Kolmogorov distribution (which I call 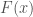

There is no known simpler form and we have to work with this sum as it is. This is an infinite sum. How can we compute the value of this infinite sum numerically?
Naïvely we can do the following:
summand <- function(x, k) sqrt(2 * pi)/x * exp(-(2 * k - 1)^2 * pi^2/(8 * x^2)) # Compute F(1) sum(summand(1, 1:500))
[1] 0.7300003
In other words, sum up many of the terms and you should be close to the actual infinite sum.
This is a crude approach. The answer is not wrong (numerically) but certainly we should understand why adding up that many terms works. Also, we could have added more terms than necessary… or not enough.
So how can we compute this sum that guarantees some level of precision while at the same time not adding any more terms than necessary? Unfortunately I don’t recall how to do this from my numerical methods classes, but I believe I have found an approach that works well enough for my purposes.
Geometric Sums
An infinite sum is defined as the limit of a sequence of finite sums. Let 
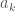




My attempt to compute this sum simply amounts to trying to find an 




Since we don’t know what 


Every sum that converges requires the condition 
Take the case of a geometric series:

with 

After some algebra, we can quickly find a rule for determining how many summands we need to attain “numerical convergence”:

We can see that in action with some R examples:
.Machine$double.eps # Numerical accuracy of this system
[1] 2.220446e-16
log(.Machine$double.eps)/log(0.5)
[1] 52
sum(0.5^(0:53))
[1] 2
# 2 is the correct answer, but the interpreter rounds its output; is the answer # actually 2? sum(0.5^(0:53)) - 2 == 0
[1] TRUE
sum(0.5^(0:52)) - 2 == 0
[1] FALSE
Caveats
This method, though, should be met with suspicion. For instance, it will not work for a slowly convergent sum. Take for example 

.Machine$double.eps^(-1/2)
[1] 67108864
N <- 67108865 sum((1:N)^(-2)) # This may take a while
[1] 1.644934
sum((1:N)^(-2)) - pi^2/6
[1] -1.490116e-08
That difference is much larger than numerical accuracy.
In fact, the technique doesn’t always work for geometric sums either, as demonstrated by these examples.1
sum(.99^(0:4000)) - 100
[1] -8.526513e-14
sum(.999^(0:40000)) - 1000
[1] -9.094947e-13
Conclusion
However, while this method cannot guarantee quick convergence or even convergence, I think it’s good enough for the sum I want to compute.
First, the sum converges more quickly than a geometric sum, as the summand decrease at a rate of 

sum(), since the latter is implemented using fast C code. Such an implementation would have to be written from scratch in C++ using a tool such as Rcpp. One must wonder whether the tiny numerical efficiency and speed one might potentially gain are worth the work; if x is large it may be best to just round off the CDF at 1.
In the end, using the lessons learned above, I implemented the Kolmogorov distribution in the package I’m writing for my current research project with the code below.
pkolmogorov <- function(q, summands = ceiling(q * sqrt(72) + 3/2)) {
sqrt(2 * pi) * sapply(q, function(x) { if (x > 0) {
sum(exp(-(2 * (1:summands) - 1)^2 * pi^2/(8 * x^2)))/x
} else {
0
}})
}
pkolmogorov <- Vectorize(pkolmogorov, "q")
Numerical summation, as I mentioned above, is something I know little about, so I’d appreciate any readers with thoughts on this topic (and knowledge of how this is done in R) to share in the comments.
I have created a video course published by Packt Publishing entitled Training Your Systems with Python Statistical Modelling, the third volume in a four-volume set of video courses entitled, Taming Data with Python; Excelling as a Data Analyst. This course discusses how to use Python for machine learning. The course covers classical statistical methods, supervised learning including classification and regression, clustering, dimensionality reduction, and more! The course is peppered with examples demonstrating the techniques and software on real-world data and visuals to explain the concepts presented. Viewers get a hands-on experience using Python for machine learning. If you are starting out using Python for data analysis or know someone who is, please consider buying my course or at least spreading the word about it. You can buy the course directly or purchase a subscription to Mapt and watch it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)! Also, stay tuned for future courses I publish with Packt at the Video Courses section of my site.
- If you’re keeping score at home you’ll notice these sums use many more terms than the rule I describe above suggests, suggesting that the problem is not just that the “stopping” rule is wrong but that adding more terms from the sum won’t lead to greater numerical accuracy since the terms being added are essentially zero. Something else will need to be done, going beyond just adding more terms. ↩

2 thoughts on “Naïve Numerical Sums in R”