UPDATE (11/2/17 3:00 PM MDT): I got the following e-mail from Brian Peterson, a well-known R finance contributor, over R’s finance mailing list:
I would strongly suggest looking at rugarch or rmgarch. The primary
maintainer of the RMetrics suite of packages, Diethelm Wuertz, was
killed in a car crash in 2016. That code is basically unmaintained.
I will see if this solves the problem. Thanks Brian! I’m leaving this post up though as a warning to others to avoid fGarch in the future. This was news to me, books often refer to fGarch, so this could be a resource for those looking for working with GARCH models in R why not to use fGarch.
UPDATE (11/2/17 11:30 PM MDT): I tried a quick experiment with rugarch and it appears to be plagued by this problem as well. Below is some quick code I ran. I may post a full study as soon as tomorrow.
library(rugarch)
spec = ugarchspec(variance.model = list(garchOrder = c(1, 1)), mean.model = list(armaOrder = c(0, 0), include.mean = FALSE), fixed.pars = list(alpha1 = 0.2, beta1 = 0.2, omega = 0.2))
ugarchpath(spec = spec, n.sim = 1000, n.start = 1000) -> x
srs = x@path$seriesSim
spec1 = ugarchspec(variance.model = list(garchOrder = c(1, 1)), mean.model = list(armaOrder = c(0, 0), include.mean = FALSE))
ugarchfit(spec = spec1, data = srs)
ugarchfit(spec = spec1, data = srs[1:100])
These days my research focuses on change point detection methods. These are statistical tests and procedures to detect a structural change in a sequence of data. An early example, from quality control, is detecting whether a machine became uncalibrated when producing a widget. There may be some measurement of interest, such as the diameter of a ball bearing, that we observe. The machine produces these widgets in sequence. Under the null hypothesis, the ball bearing’s mean diameter does not change, while under the alternative, at some unkown point in the manufacturing process the machine became uncalibrated and the mean diameter of the ball bearings changed. The test then decides between these two hypotheses.
Continue reading →


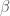 ) and perceived pathological behavior when those estimates are computed using fGarch. I called for help from the R community, including sending out the blog post over the
) and perceived pathological behavior when those estimates are computed using fGarch. I called for help from the R community, including sending out the blog post over the