
Introduction
This article is also available in PDF form.
A while back someone posted on Reddit about the grading policies of their academic department. Specifically, the department chair made a statement claiming that grades should be Normally distributed with a C average. I responded, claiming that no statistician would ever take the idea that grades follow a Normal distribution seriously. Some asked for context, and I wrote a long response explaining my position. I repeat that argument here, and also give some R code demonstrations showing what curving grades does. Continue reading





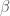 ) and perceived pathological behavior when those estimates are computed using fGarch. I called for help from the R community, including sending out the blog post over the
) and perceived pathological behavior when those estimates are computed using fGarch. I called for help from the R community, including sending out the blog post over the 

