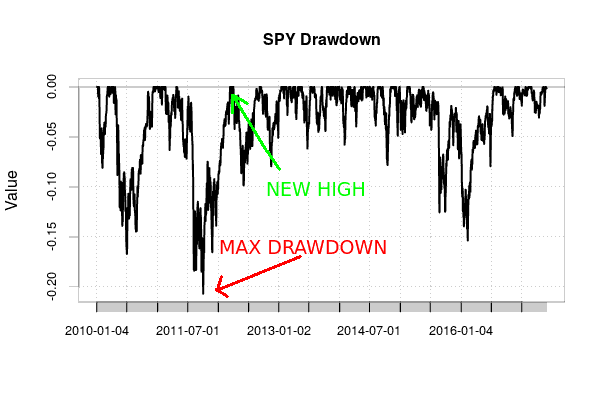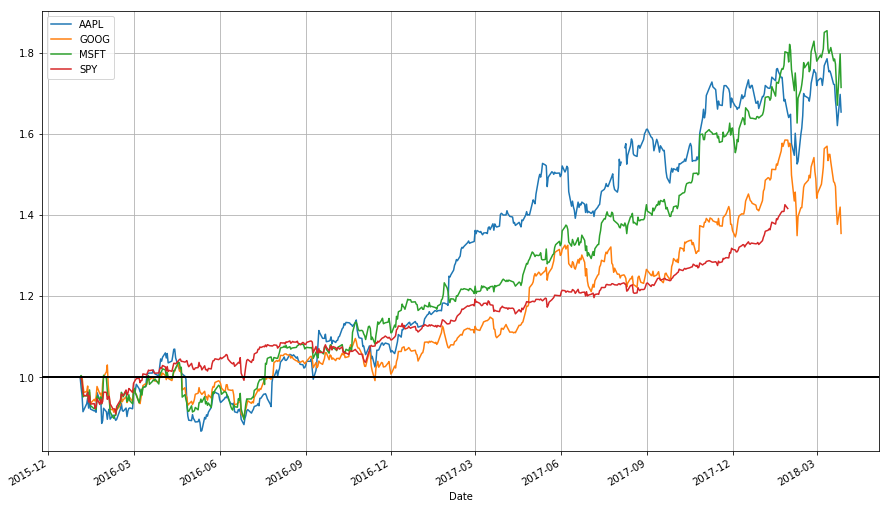
Introduction
This is a lecture for MATH 4100/CS 5160: Introduction to Data Science, offered at the University of Utah, introducing time series data analysis applied to finance. This is also an update to my earlier blog posts on the same topic (this one combining them together). I strongly advise referring to this blog post instead of the previous ones (which I am not altering for the sake of preserving a record). The code should work as of July 7th, 2018. (And sorry for some of the formatting; WordPress.com’s free version doesn’t play nice with code or tables.)