Packt Publishing has turned another one of my video courses, Training Your Systems with Python Statistical Modeling, into a book! This book is now available for purchase.

Packt Publishing has turned another one of my video courses, Training Your Systems with Python Statistical Modeling, into a book! This book is now available for purchase.

This article is also available in PDF form.
I started my first research project as a graduate student when I was only in the MSTAT program at the University of Utah, at the very end of 2015 (or very beginning of 2016; not sure exactly when) with my current advisor, Lajos Horváth. While I am disappointed it took this long, I am glad to say that the project is finished and I am finally published.

Months ago, I asked a question to the community: how should I organize my R research projects? After writing that post, doing some reading, then putting a plan in practice, I now have my own answer.

Now here is a blog post that has been sitting on the shelf far longer than it should have. Over a year ago I wrote an article about problems I was having when estimating the parameters of a GARCH(1,1) model in R. I documented the behavior of parameter estimates (with a focus on 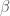
Over the past few weeks I’ve published articles about my new package, MCHT, starting with an introduction, a further technical discussion, demonstrating maximized Monte Carlo (MMC) hypothesis testing, bootstrap hypothesis testing, and last week I showed how to handle multi-sample and multivariate data. This is the final article where I explain the capabilities of the package. I show how MCHT can handle time series data.

I’ve spent the past few weeks writing about MCHT, my new package for Monte Carlo and bootstrap hypothesis testing. After discussing how to use MCHT safely, I discussed how to use it for maximized Monte Carlo (MMC) testing, then bootstrap testing. One may think I’ve said all I want to say about the package, but in truth, I’ve only barely passed the halfway point!

I announced months ago that one of my video courses, Unpacking NumPy and Pandas, was going to be turned into a book. Today I’m pleased to announce that this book is available!
Today is the first day of the new academic year at the University of Utah. This semester I am teaching MATH 3070: Applied Statistics I, the fourth time I’ve taught this course.

I’m pleased to announce my fourth and final video course. The course has already been out for a couple months by now, but that doesn’t mean it’s too late for me to write about it!
I’m reblogging this article mostly for myself. If you’ve been following my blog, you’ll see that recently I published an article on organizing R code that mentioned using packages to organize that code. One of the advantages of doing so is that the work you’ve done is easily distributed. If the methods are novel in some way, you may even get a paper in J. Stat. Soft. or the R Journal that helps people learn how to use your software and exposes the methodology to a wider audience. Therefore we should know something about those journals. (I recently got a good reply on Reddit about the difference between these journals.)
When I was considering submitting my paper on psd to J. Stat. Soft. (JSS), I kept noticing that the time from “Submitted” to “Accepted” was nearly two years in many cases. I ultimately decided that was much too long of a review process, no matter what the impact factor might be (and in two years time, would I even care?). Tonight I had the sudden urge to put together a dataset of times to publication.
Fortunately the JSS website is structured such that it only took a few minutes playing with XML scraping (*shudder*) to write the (R) code to reproduce the full dataset. I then ran a changepoint (published in JSS!) analysis to see when shifts in mean time have occurred. Here are the results:
 Top: The number of days for a paper to go from ‘Submitted’ to ‘Accepted’ as a function of the cumulative issue index (each paper is an “issue”…
Top: The number of days for a paper to go from ‘Submitted’ to ‘Accepted’ as a function of the cumulative issue index (each paper is an “issue”…
View original post 152 more words
