I am very excited to announce my first (public) package (and the second package I’ve ever written, the first being unannounced until the accompanying paper is accepted). That package is MCHT, a package for bootstrap and Monte Carlo hypothesis testing, currently available on GitHub.
This will be the first of a series of blog posts introducing the package. Most of the examples in the blog posts are already present in the manual, but I plan to go into more depth here, including some background and more detailed explanations.
MCHT is a package implementing an interface for creating and using Monte Carlo tests. The primary function of the package is MCHTest(), which creates functions with S3 class MCHTest that perform a Monte Carlo test.
Installation
MCHT is not presently available on CRAN. You can download and install MCHT from GitHub using devtools via the R command devtools::install_github("ntguardian/MCHT").
Monte Carlo Hypothesis Testing
Monte Carlo testing is a form of hypothesis testing where the 
Suppose that 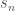




Instead of using 



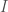


The power of these tests increase with 
MCHTest() are the tests described in [2].) Unfortunately, MMC, while conservative and exact, has much less power than if the unknown parameters were known, perhaps due to the behavior of samples under distributions with parameter values distant from the true parameter values (see [3]).
Bootstrap Hypothesis Testing
Bootstrap statistical testing is very similar to Monte Carlo testing; the key difference is that bootstrap testing uses information from the sample. For example a parametric bootstrap test would estimate the parameters of the distribution the data is assumed to follow and generate datasets from that distribution using those estimates as the actual parameter values. A permutation test (like Fisher’s permutation test; see [4]) would use the original dataset values but randomly shuffle the labeles (stating which sample an observation belongs to) to generate new data sets and thus new simulated test statistics.
Unlike Monte Carlo tests and MMC, these tests are not exact tests. That said, they often have good finite sample properties. (See [3].) See the documentation mentioned above for more details and references.
Motivation
Why write a package for these types of tests? This is not the only package that facilitates bootstrapping or Monte Carlo testing. The website RDocumentation includes documentation for the package MChtest, by Michael Fay which exists for Monte Carlo testing, too. The package MaxMC by Julien Neves is devoted to MMC specifically, as described by [2]. Then there’s the package boot, which is intended to facilitate bootstrapping. (If I’m missing anything, please let me know in the comments.)
MChtest is no longer on CRAN and implements a particular form of Monte Carlo testing and thus does not work for MMC. MaxMC appears to be in a very raw state. boot seems general enough that it could be used for bootstrap testing but still seems more geared towards constructing bootstrap confidence intervals and standard errors rather than hypothesis testing. All of these have a very different architecture from MCHT, which is primarily for creating a function like t.test() that performs a hypothesis test that was described when the function was created.
Additionally, this was good practice in practicing package development and more advanced R programming. This is the first time I made serious use of closures, S3 classes and R’s flavor of object-oriented programming, and environments. So far the result seems to be an flexible and robust tool for performing tests based on randomization.
Getting Started
Let’s start with a “Hello, world!”-esque example for a Monte Carlo test: a Monte Carlo version of the 
The one-sample 


(The alternative could also be one-sided, perhaps instead stating 
t.test(), but the moment we drop this assumption there is an opening for Monte Carlo testing to be useful.
Let’s load up the package.
library(MCHT)
## .------..------..------..------.
## |M.--. ||C.--. ||H.--. ||T.--. |
## | (\/) || :/\: || :/\: || :/\: |
## | :\/: || :\/: || (__) || (__) |
## | '--'M|| '--'C|| '--'H|| '--'T|
## `------'`------'`------'`------' v. 0.1.0
## Type citation("MCHT") for citing this R package in publications
(Yes, I’ve got a cute little .onAttach() package start-up message. I first saw a message like this implemented by mclust and of course Stata’s start-up message and thought they’re so adorable that I will likely add such messages to all my packages. You can use suppressPackageStartupMessages() to make this quiet if you want. Thanks to the Python package art for the cool ASCII art.)
The star function of the pacakge is the MCHTest() function.
args(MCHTest)
## function (test_stat, stat_gen, rand_gen = function(n) {
## stats::runif(n)
## }, N = 10000, seed = NULL, memoise_sample = TRUE, pval_func = MCHT::pval,
## method = "Monte Carlo Test", test_params = NULL, fixed_params = NULL,
## nuisance_params = NULL, optim_control = NULL, tiebreaking = FALSE,
## lock_alternative = TRUE, threshold_pval = 1, suppress_threshold_warning = FALSE,
## localize_functions = FALSE, imported_objects = NULL)
## NULL
The documentation for this function is the majority of the manual and I’ve written multiple examples demonstrating its use. In short, a single call to MCHTest() will create an MCHTest-S3-class object (which is just a function) that can be use for hypothesis testing. Three arguments (all of which are functions) passed to the call will characterize the resulting test:
test_stat: A function with an argumentxthat computes the test statistic, withxbeing the argument that accepts the dataset from which to compute the test statistic.rand_gen: A function generating random datasets, and must have either an argumentxthat would accept the original dataset or an argumentnthat represents the size of the dataset.stat_gen: A function with an argumentxthat will take the random numbers generated byrand_genand turn them into a simulated test statistic. Sometimesstat_genis the same astest_stat, but it is better to write separate functions, as will be seen later.
The functions passed to these arguments can accept other parameters, particularly parameters describing test parameters (that is, the parameter values we are testing, such as the population mean 

MCHTest() parameters that can be used for recognizing them: test_params, fixed_params, and nuisance_params, respectively. While one could in principle ignore these parameters and pass functions to test_stat, stat_gen, and rand_gen that use them anyway, I would recommend not doing so. First, there’s no guarantee that MCHTest-class objects would handle the extra parameters correctly. Second, when MCHTest() is made aware of these special cases, it can check that the functions passed to test_stat, stat_gen, and rand_gen handle these types of parameters correctly and will throw an error when it appears they do not. This safety measure helps you use MCHT correctly.
Carrying on, let’s create our first MCHTest object for a
ts <- function(x) {
sqrt(length(x)) * mean(x)/sd(x)
}
mc.t.test.1 <- MCHTest(ts, ts, rnorm, N = 10000, seed = 123)
Above, both test_stat and stat_gen are ts() (they're the first and second arguments, respectively) and the random number generator rand_gen is rnorm(). Two other parameters are:
N: the number of simulated test statistics to generate.seed: the seed of the random number generator, which makes test results consistent and reproducible.
MCHTest-class objects have a print() method that summarize how the object was defined. We see it in action here:
mc.t.test.1
## ## Details for Monte Carlo Test ## ## Seed: 123 ## Replications: 10000 ## ## Memoisation enabled ## Argument "alternative" is locked
This will tell us the seed being used and the number of replicates used for hypothesis testing, along with other messages. I want to draw attention to the message Argument "alternative" is locked. This means that the test we just created will ignore anything passed to the parameter alternative (similar to the parameter of the same name t.test() has). We can enable that parameter by setting the MCHTest() parameter lock_alternative to FALSE.
(mc.t.test.1 <- MCHTest(ts, ts, rnorm, N = 10000, seed = 123,
lock_alternative = FALSE))
## ## Details for Monte Carlo Test ## ## Seed: 123 ## Replications: 10000 ## ## Memoisation enabled
Let's now try this function out on data.
dat <- c(0.27, 0.04, 1.37, 0.23, 0.34, 1.44, 0.34, 4.05, 1.59, 1.54) mc.t.test.1(dat)
## ## Monte Carlo Test ## ## data: dat ## S = 2.9445, p-value = 0.0072
If you run the above code you may see a complaint about %dopar% being run sequentially. This complaint appears when we don't register CPU cores for parallelization. MCHT uses foreach, doParallel, and doRNG to parallelize simulations and thus hopefully speed them up. Simulations can take a long time and parallelization can help make the process faster. If we were to continue we would not see the complaint again; R accepts that there's only one core visible and thus doesn't parallelize. But we can register the other cores on our system with the following:
library(doParallel) registerDoParallel(detectCores())
Not only do we have parallelization enabled, MCHTest() automatically enables memoization so that it doesn't redo simulations if the data (or at least the data's sample size) hasn't changed. (This can be turned off by setting the MCHTest() parameter memoise-sample to FALSE.) Again, this is so that we save time and don't have to fear repeat usage of our MCHTest-class function.
The above test effectively checked whether the population mean was zero against the alternative that the population mean is greater than zero (due to the default behaviour when alternative is not specified). By changing the alternative parameter we can test against other alternative hypotheses.
mc.t.test.1(dat, alternative = "less")
## ## Monte Carlo Test ## ## data: dat ## S = 2.9445, p-value = 0.9928 ## alternative hypothesis: less
mc.t.test.1(dat, alternative = "two.sided")
## ## Monte Carlo Test ## ## data: dat ## S = 2.9445, p-value = 0.0144 ## alternative hypothesis: two.sided
Compare this to t.test().
t.test(dat, alternative = "two.sided")
## ## One Sample t-test ## ## data: dat ## t = 2.9445, df = 9, p-value = 0.01637 ## alternative hypothesis: true mean is not equal to 0 ## 95 percent confidence interval: ## 0.2597649 1.9822351 ## sample estimates: ## mean of x ## 1.121
The two tests reach similar conclusions.
However, t.test() is an exact and most-powerful test at any sample size under the assumptions we made. But all we need to do is not assume the data was drawn from a Gaussian distribution to throw the
I know for a fact that dat was generated using an exponential distribution, so let's write a new version of the
ts <- function(x, mu = 1) {
# Throw an error if mu is not positive; exponential random variables have only
# positive mu
if (mu <= 0) stop("mu must be positive")
sqrt(length(x)) * (mean(x) - mu)/sd(x)
}
sg <- function(x, mu = 1) {
x <- mu * x
sqrt(length(x)) * (mean(x) - mu)/sd(x)
}
(mc.t.test.2 <- MCHTest(ts, sg, rexp, seed = 123,
method = "One-Sample Monte Carlo Exponential t-Test",
test_params = "mu", lock_alternative = FALSE))
## ## Details for One-Sample Monte Carlo Exponential t-Test ## ## Seed: 123 ## Replications: 10000 ## Tested Parameters: mu ## Default mu: 1 ## ## Memoisation enabled
Using this new function works the same, only now we can specify the
mc.t.test.2(dat, mu = 2, alternative = "two.sided")
## ## One-Sample Monte Carlo Exponential t-Test ## ## data: dat ## S = -2.3088, p-value = 0.181 ## alternative hypothesis: true mu is not equal to 2
mc.t.test.2(dat, mu = 1, alternative = "two.sided")
## ## One-Sample Monte Carlo Exponential t-Test ## ## data: dat ## S = 0.31782, p-value = 0.6888 ## alternative hypothesis: true mu is not equal to 1
t.test(dat, mu = 1, alternative = "two.sided")
## ## One Sample t-test ## ## data: dat ## t = 0.31782, df = 9, p-value = 0.7579 ## alternative hypothesis: true mean is not equal to 1 ## 95 percent confidence interval: ## 0.2597649 1.9822351 ## sample estimates: ## mean of x ## 1.121
Now the
Conclusion
I would consider the current release of MCHT to be early beta; it is usable but it's not yet able to be considered "stable". Keep that in mind if you plan to use it.
I'm very excited about this package and look forward to writing more about it. Stay tuned for future blog posts explaining its functionality. It's highly likely it has strange and mysterious behavior so I hope that if anyone encounters strange behavior, they report it and help push MCHT closer to a "stable" state.
I'm early in my academic career (in that I'm a Ph.D. student without any of my own publications yet), and I'm unsure if this package is worth a paper in, say, J. Stat. Soft. or the R Journal (heck, I'd even write a book about the package if it deserved it). I'd love to hear comments on any future publications that others would want to see.
Thanks for reading and stay tuned!
Next post: making MCHTest objects self-contained.
References
- A. C. A. Hope, A simplified Monte Carlo test procedure, JRSSB, vol. 30 (1968) pp. 582-598
- J-M Dufour, Monte Carlo tests with nuisance parameters: A general approach to finite-sample inference and nonstandard asymptotics, Journal of Econometrics, vol. 133 no. 2 (2006) pp. 443-477
- J. G. MacKinnon, Bootstrap hypothesis testing in Handbook of computational econometrics (2009) pp. 183-213
- R. A. Fisher, The design of experiments (1935)
- R. Davidson and J. G. MacKinnon, The size distortion of bootstrap test, Econometric Theory, vol. 15 (1999) pp. 361-376
Packt Publishing published a book for me entitled Hands-On Data Analysis with NumPy and Pandas, a book based on my video course Unpacking NumPy and Pandas. This book covers the basics of setting up a Python environment for data analysis with Anaconda, using Jupyter notebooks, and using NumPy and pandas. If you are starting out using Python for data analysis or know someone who is, please consider buying my book or at least spreading the word about it. You can buy the book directly or purchase a subscription to Mapt and read it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)!

Hello, thanks for nice blog post! Have you heard about infer package https://www.rdocumentation.org/packages/infer/versions/0.3.1? It’s package intended for stat inference with bootstrap, simulation, and permutation using the logic of tidyverse. I think it’s aimed towards audience who may not have as much experience with these procedures…
LikeLiked by 1 person
Thanks for pointing this out to me! I was not aware of the existence of this package. This package wants to use the tidyverse style, while my package doesn’t. infer can compute confidence intervals while MCHT is devoted exclusively to hypothesis testing. infer seems to view random testing via a grammar while MCHT views it basically as a recipe with a few ingredients, and all that are needed are those ingredients. MCHT produces functions resembling base R test functions which are responsible for doing the test, while infer calls for writing out the whole process. Also, infer does not support maximized Monte Carlo.
LikeLike